목차
1. 들어가며
1.1. 트랜잭션이란
트랜잭션은 데이터베이스의 상태를 변화시키는 하나의 논리적 작업 단위다.
은행에서 계좌 이체를 예로 들면, '출금'과 '입금'이라는 두 작업이 하나의 트랜잭션으로 묶여 처리된다. 이 두 작업은 모두 성공하거나 모두 실패해야만 한다. 만약 출금은 됐는데 입금이 실패한다면, 돈이 사라지는 심각한 문제가 발생할 수 있기 때문이다.
1.2. ACID와 BASE의 개념
이러한 트랜잭션을 어떻게 처리할 것인가에 대한 접근 방식이 바로 ACID와 BASE다.

- ACID는 관계형 데이터베이스에서 트랜잭션의 안전성과 신뢰성을 보장하기 위한 속성들을 정의한 모델이다.
- BASE는 분산 시스템, 특히 NoSQL 데이터베이스에서 데이터 일관성을 다루는 방식을 설명하는 모델이다.
이를 구분하는 핵심은 시스템의 목표(일관성 vs 가용성) 와 사용 환경이다.
ACID와 BASE의 차이점을 이해하면 시스템 설계 시 요구사항에 맞는 데이터베이스를 선택할 수 있다.
1.3. 이러한 모델이 필요한 이유
현대 시스템은 수많은 사용자의 요청을 동시에 처리해야 한다. 온라인 쇼핑몰에서 동시에 여러 고객이 같은 상품을 구매하거나, SNS에서 수많은 사용자가 동시에 게시물을 업로드하는 상황이 발생한다.
이때 시스템의 특성에 따라
- 데이터의 정확성과 일관성을 어떻게 보장할 것인지,
- 또는 일시적인 불일치를 허용하더라도 가용성과 성능을 우선시할 것인지
선택해야 한다.
은행 시스템처럼 데이터 정확성이 절대적으로 중요한 경우에는 ACID 특성을 반드시 우선해야 한다. 반면 SNS 피드처럼 일시적인 데이터 불일치가 허용되는 경우에는 BASE 모델이 더 적합할 수 있다.
예를 들어, 결제 시스템은 금액의 정확성이 절대적으로 중요하므로 ACID 트랜잭션이 필수적이다. 반면, 유튜브 조회수 같은 경우는 실시간 정확성보다는 시스템의 가용성이 더 중요할 수 있으므로 BASE 모델을 선택할 수 있다. 이러한 선택은 시스템의 성능, 확장성, 유지보수성에 직접적인 영향을 미치게 된다.
이어지는 내용에서는 ACID 트랜잭션의 특성과 BASE 일관성 모델의 특성을 자세히 살펴보면서, 어떤 상황에서 어떤 모델을 선택하는 것이 좋을지 알아보도록 하겠다.
2. ACID
2.1. ACID 개념 소개
ACID는 트랜잭션의 4가지 특성을 나타내는 약자로, 원자성, 일관성, 격리성, 지속성을 의미한다.
2.1.1. Atomicity (원자성)
원자성은 트랜잭션의 작업이 "모두 반영되거나 전혀 반영되지 않아야 한다"는 특성이다.

예시:
- 계좌 이체 시나리오
- A계좌에서 10만원 출금
- B계좌에 10만원 입금
이 두 작업은 반드시 함께 성공하거나 함께 실패해야 한다. 만약 1번 작업 후 2번 작업이 실패하면, 1번 작업도 취소(rollback)되어야 한다.
2.1.2. Consistency (일관성)
일관성은 트랜잭션 실행 전과 후의 데이터베이스가 모두 일관된 상태여야 한다는 특성이다.
일관된 상태란, 데이터베이스의 모든 데이터가 모순되지 않는 상태를 의미한다.

예시:
- 계좌 잔고는 항상 0원 이상이어야 한다는 비즈니스 규칙이 있다면
- 트랜잭션 실행 전/후 모두 이 규칙이 지켜져야 함
- 규칙을 위반하는 트랜잭션은 실행될 수 없음
2.1.3. Isolation (격리성)
격리성은 동시에 실행되는 트랜잭션들이 서로 영향을 미치지 않도록 격리되어야 한다는 특성이다.

예를 들어, 두 사용자가 동시에 같은 데이터를 수정하려 할 때:
- 사용자A: 계좌 잔고 1000원 확인 → 500원 출금 시도
- 사용자B: 동시에 같은 계좌 잔고 1000원 확인 → 800원 출금 시도
이 경우, 사용자A와 사용자B가 동시에 출금을 시도하면 둘 중 하나는 실패해야 한다.
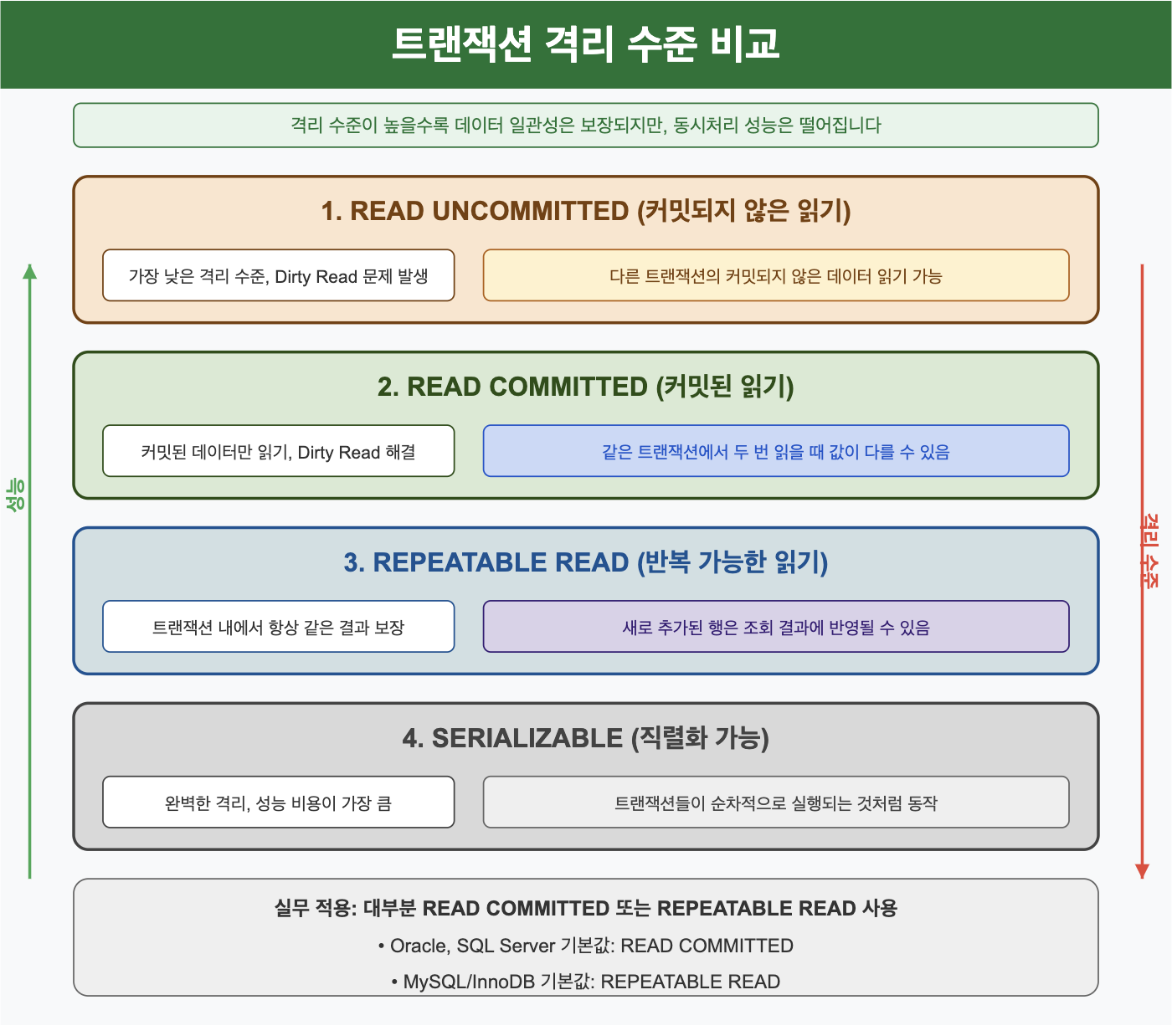
격리 수준은 아래 4가지로 나뉜다.
- READ UNCOMMITTED (커밋되지 않은 읽기)
- 가장 낮은 격리 수준
- 다른 트랜잭션이 커밋하지 않은 데이터도 읽을 수 있음
- Dirty Read 문제 발생 가능 (다른 트랜잭션이 롤백한 데이터를 읽을 수 있는 문제)
- READ COMMITTED (커밋된 읽기)
- 커밋된 데이터만 읽을 수 있음
- 하나의 트랜잭션 내에서 같은 SELECT 문이 다른 결과를 반환할 수 있음
- REPEATABLE READ (반복 가능한 읽기)
- 트랜잭션이 시작되기 전에 커밋된 내용만 보임
- 같은 트랜잭션 내에서는 항상 같은 결과 보장
- SERIALIZABLE (직렬화 가능)
- 가장 높은 격리 수준
- 완벽한 읽기 일관성 제공
- 성능 비용이 가장 큼
격리 수준이 높을수록 데이터 일관성은 보장되지만, 동시처리 성능은 떨어진다.

2.1.4. Durability (지속성)
지속성은 성공적으로 완료된 트랜잭션의 결과는 영구적으로 반영되어야 한다는 특성이다.
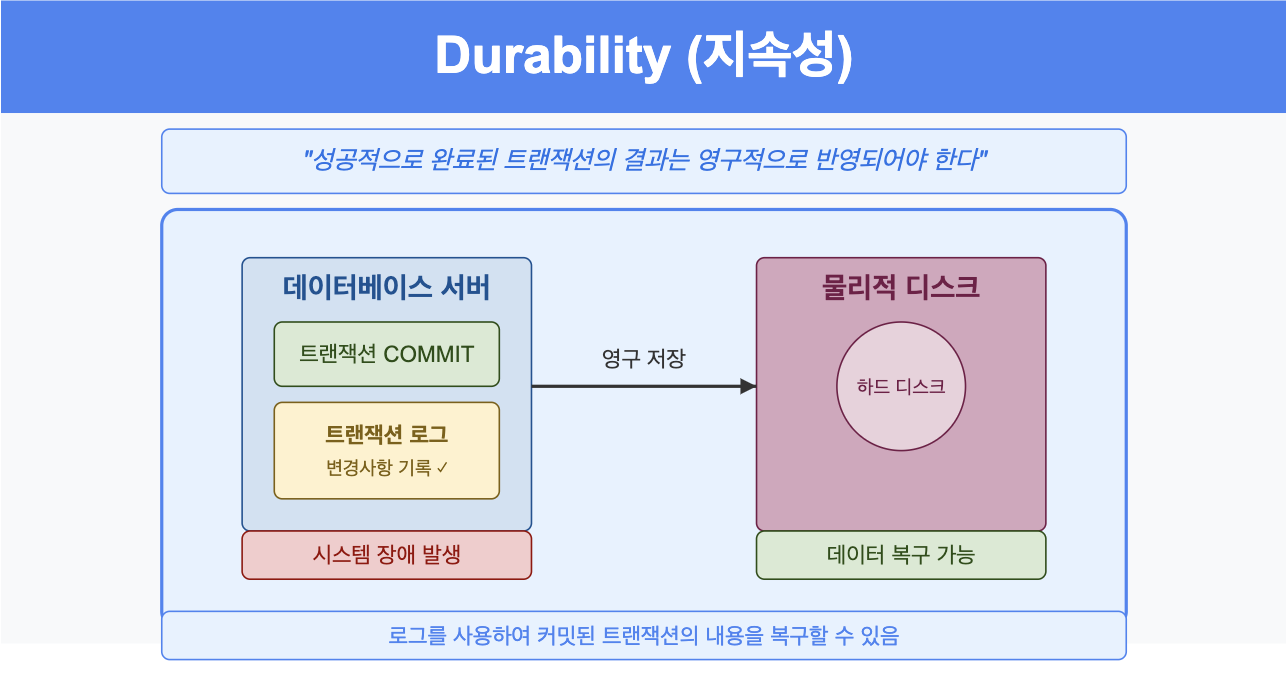
- 시스템 장애가 발생하더라도 커밋된 트랜잭션의 내용은 보존
- 주로 데이터베이스의 로그를 통해 구현
2.2. ACID가 적합한 시스템 요구사항 및 사례
ACID 트랜잭션은 데이터의 무결성과 일관성이 매우 중요한 시스템에서 사용된다. 아래는 ACID가 적합한 주요 시스템 요구사항과 실제 사용 사례이다.
2.2.1. ACID가 적합한 시스템 요구사항
- 금융 거래 시스템
- 은행 계좌 이체, 대출 처리 등에서 데이터의 정확성과 신뢰성이 필수적이다.
- 예: A 계좌에서 B 계좌로 송금 시, 출금과 입금이 모두 성공해야만 트랜잭션이 완료된다.
- 주문 처리 시스템
- 전자상거래에서 주문 생성, 결제 처리, 재고 감소 등의 작업이 모두 성공적으로 이루어져야 한다.
- 예: 고객이 상품을 주문할 때, 결제와 재고 업데이트가 모두 성공해야 한다.
- 재고 관리 시스템
- 재고 추가 또는 감소 시 데이터 일관성을 유지해야 한다.
- 예: 물류 창고에서 상품 출고 시 재고 수량이 정확히 반영되어야 한다.
- 예약 시스템
- 항공권 예약, 호텔 예약 등에서 동일한 좌석이나 방을 여러 사용자가 동시에 예약하지 못하도록 보장한다.
- 예: 트랜잭션 격리성을 통해 중복 예약을 방지한다.
- 웹 서버 세션 관리
- 사용자 세션 데이터를 안전하게 저장하고 업데이트하여 세션 무결성을 유지한다.
2.2.2. 대표 데이터베이스
- RDBMS(Relational Database Management System)
- MySQL, PostgreSQL, Oracle DB 등은 ACID 트랜잭션을 지원하며, 금융 및 기업 애플리케이션에서 널리 사용한다.
- PostgreSQL은 직렬화 가능한 격리 수준을 제공하여 가장 높은 일관성을 보장한다.
- Delta Lake
- 데이터 웨어하우스와 데이터 레이크를 통합하며, 실시간 데이터 처리에서도 ACID 속성을 유지한다.
2.2.3. 예제
다음은 MySQL에서 계좌 이체를 구현하는 간단한 ACID 트랜잭션이다.
-- 트랜잭션 시작
BEGIN;
-- A 계좌에서 100을 차감
UPDATE accounts SET balance = balance - 100 WHERE account_id = 1;
-- B 계좌에 100을 추가
UPDATE accounts SET balance = balance + 100 WHERE account_id = 2;
-- 모든 작업이 성공하면 커밋
COMMIT;
-- 오류 발생 시 롤백
ROLLBACK;코드 설명
BEGIN;으로 트랜잭션을 시작한다.- 첫 번째
UPDATE는 A 계좌의 잔액을 차감한다. - 두 번째
UPDATE는 B 계좌의 잔액을 증가시킨다. - 모든 작업이 성공하면
COMMIT;으로 변경 사항을 확정한다. - 오류 발생 시
ROLLBACK;으로 모든 변경 사항을 취소하여 원래 상태로 복구한다.
2.3. 요약
| 속성 | ACID |
|---|---|
| 일관성 수준 | 강한 일관성 (Strong Consistency) |
| 중점 사항 | 데이터 정확성과 신뢰성 |
| 적용 환경 | 단일/분산 RDBMS |
| 사용 사례 | 금융 거래, 재고 관리, 예약 시스템 |
| 대표 기술 | MySQL, PostgreSQL, Oracle |
- ACID는 데이터 무결성과 일관성이 중요한 금융, 주문, 예약 시스템 등에 적합하다.
- MySQL, PostgreSQL 같은 RDBMS는 ACID 속성을 기본적으로 지원하며, SQL 명령(
BEGIN,COMMIT,ROLLBACK)으로 쉽게 구현할 수 있다. - 이러한 특성은 특히 데이터 손실이나 오류를 허용할 수 없는 환경에서 필수적이다.
ACID 트랜잭션은 안정성과 신뢰성이 중요한 시스템에서 필수적인 선택이며, 이를 통해 데이터베이스의 무결성과 안정성을 보장할 수 있다.
3. BASE 트랜잭션
3.1. BASE 개념 소개
BASE는 분산 시스템에서 데이터 일관성을 다루는 대안적 모델이다. BASE는 아래 세 가지를 줄인 약자다.
3.1.1. Basically Available (기본적 가용성)

- 시스템이 항상 응답 가능한 상태를 유지함을 의미한다.
- 일부 노드에 장애가 발생하더라도 시스템은 계속 작동하며, 일시적으로 부정확한 응답을 반환할 수는 있지만 실패하지는 않는다.
- 예를 들어, SNS에서 팔로워 수가 일시적으로 정확하지 않을 수 있지만, 서비스 자체는 계속 이용 가능하다.
3.1.2. Soft state (소프트 상태)
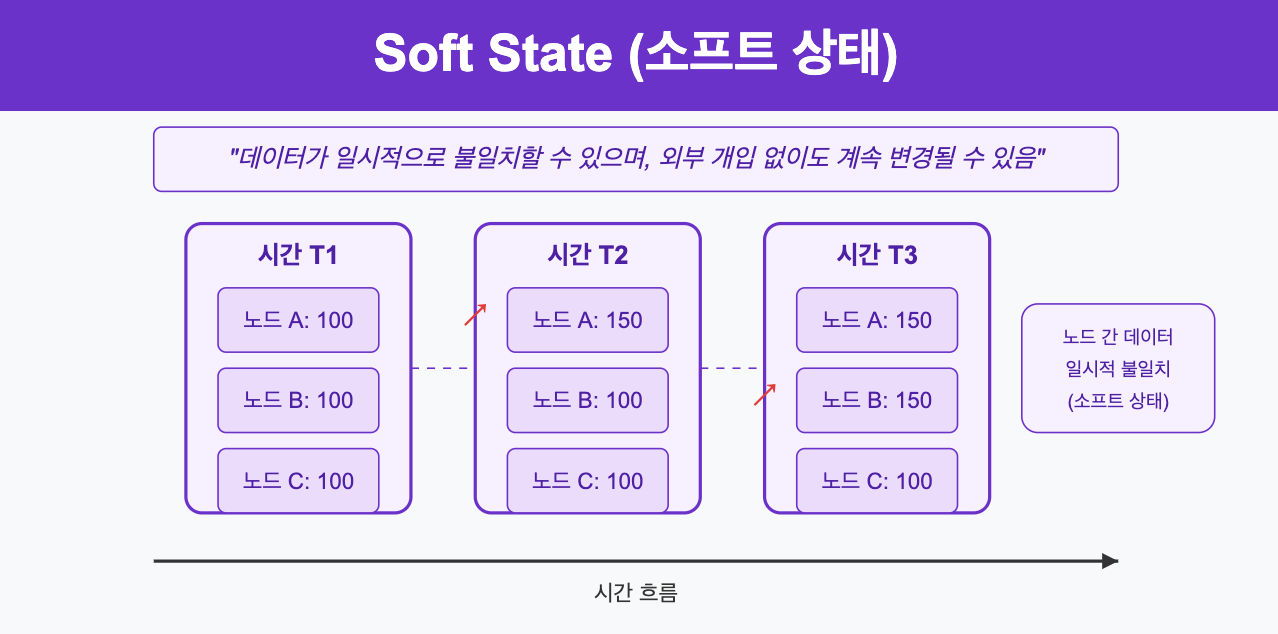
- 데이터가 일시적으로 불일치할 수 있음을 의미한다.
- 시스템은 외부의 개입 없이도 데이터가 계속 변경될 수 있으며, 각 노드의 상태가 다를 수 있다.
- 예를 들어, 유튜브 동영상의 조회수는 실시간으로 정확하지 않을 수 있으며, 시간이 지나면서 점차 정확한 값으로 수렴한다.
3.1.3. Eventually consistent (최종적 일관성)
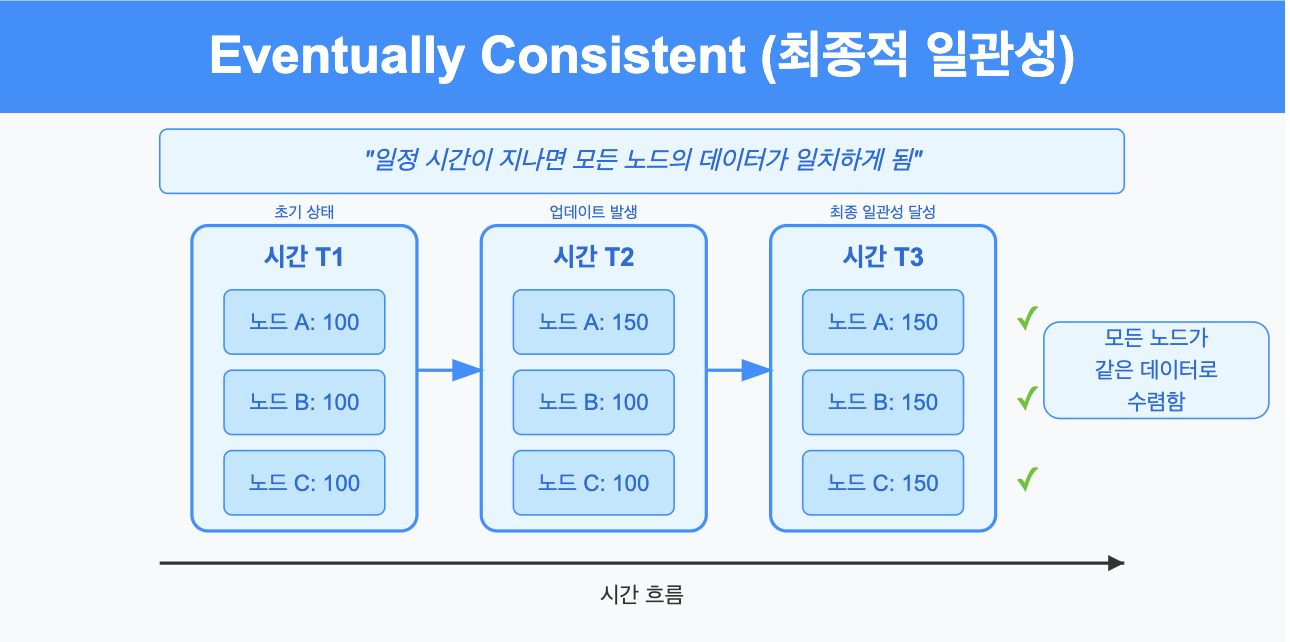
- 일정 시간이 지나면 모든 노드의 데이터가 일치하게 된다는 것을 보장한다.
- 즉, 시스템에 새로운 업데이트가 없다면, 점차적으로 모든 노드가 동일한 데이터를 가지게 된다.
- 이는 실시간 일관성보다는 느슨하지만, 결국에는 일관성을 달성한다는 점에서 중요하다.
3.2. BASE가 등장한 배경

BASE는 분산 시스템의 특성과 CAP 이론(Consistency, Availability, Partition Tolerance)의 제약에 따라 등장했다.
CAP 이론에 따르면, 분산 시스템에서는 아래 세 가지 속성을 동시에 만족시킬 수 없다고 말한다.
- Consistency (일관성): 모든 노드가 동일한 데이터를 가짐.
- Availability (가용성): 모든 요청에 대해 응답 가능.
- Partition Tolerance (분할 내성): 네트워크 장애 발생 시에도 시스템이 작동.
네트워크 분할이 불가피한 분산 환경에서는 일관성과 가용성 중 하나를 선택해야 하는데, BASE는 여기서 가용성을 선택해 분할 내성을 우선한다.
3.3. BASE가 적합한 시스템 요구사항 및 사례
3.3.1. BASE가 적합한 시스템 요구사항
BASE는 가용성과 확장성을 우선시하는 분산 시스템에서 적합하며, 데이터의 일관성이 약간 희생되더라도 빠른 응답과 높은 처리량이 필요한 환경에서 사용된다.
- SNS 피드
- 소셜 미디어에서 사용자 피드를 빠르게 로드하고 업데이트해야 하는 경우.
- 데이터 불일치(예: 댓글 수와 실제 댓글 개수 차이)가 일시적으로 허용될 수 있음.
- 예: Facebook, Twitter의 뉴스피드.
- 로그 시스템
- 대량의 로그 데이터를 빠르게 저장하고 처리해야 하는 경우.
- 데이터가 실시간으로 분석되지 않아도 되며, 나중에 일관성이 맞춰져도 무방함.
- 예: 서버 로그, 사용자 활동 기록.
- 추천 시스템
- 대규모 사용자 데이터를 기반으로 추천 알고리즘을 수행하는 경우.
- 데이터가 최종적으로 일관성을 갖추면 되고, 실시간 정확성은 덜 중요함.
- 예: Netflix의 영화 추천, Amazon의 상품 추천.
3.3.2. 대표 데이터베이스
- Cassandra
- 분산 환경에서 높은 가용성과 확장성을 제공하는 NoSQL 데이터베이스
- 최종적 일관성(Eventually Consistency) 모델 채택
- 대규모 쓰기 작업에 최적화
- 사용 사례: 시계열 데이터, 로그 데이터, IoT 센서 데이터 수집
- MongoDB
- 문서 기반 NoSQL 데이터베이스로 유연한 스키마 제공
- 복제셋(Replica Set)을 통한 고가용성 지원
- 샤딩(Sharding)을 통한 수평적 확장 가능
- 사용 사례: 실시간 분석, 콘텐츠 관리, 카탈로그 데이터
3.3.3. 예제
다음은 MongoDB를 사용하여 웹툰/웹소설 플랫폼의 조회수와 좋아요 시스템을 구현하는 BASE 트랜잭션의 예제다.
// 컬렉션 생성 및 인덱스 설정
db.createCollection("contents")
db.createCollection("content_stats")
db.contents.createIndex({ "contentId": 1 })
db.contents.createIndex({ "updatedAt": -1 })
db.content_stats.createIndex({ "contentId": 1 }, { unique: true })
// 조회수 증가 (비동기, 최종적 일관성)
db.content_stats.updateOne(
{ contentId: "webtoon123" },
{
$inc: { viewCount: 1 }
},
{
upsert: true,
writeConcern: { w: 1 } // 빠른 쓰기를 위한 낮은 수준의 쓰기 확인
}
)
// 좋아요 추가 (비동기)
db.content_stats.updateOne(
{ contentId: "webtoon123" },
{
$inc: { likeCount: 1 },
$addToSet: { likedUsers: "user456" }
},
{ upsert: true }
)
// 통계 조회 (최종적 일관성)
db.content_stats.findOne(
{ contentId: "webtoon123" },
{ readPreference: "nearest" } // 가장 가까운 노드에서 읽기
)
// 인기 콘텐츠 조회 (조회수 기준, 일시적 불일치 허용)
db.content_stats.find()
.sort({ viewCount: -1 })
.limit(10)코드 설명
- Basically Available
- writeConcern을 w:1로 설정하여 빠른 쓰기 보장
- readPreference를 nearest로 설정하여 빠른 읽기 보장
- Soft State
- 조회수와 좋아요 수가 실시간으로 정확하지 않을 수 있음
- 인기 콘텐츠 목록이 약간 지연될 수 있음
- Eventually Consistent
- 시간이 지나면 모든 데이터가 일관된 상태로 수렴
- 복제 세트(Replica Set)를 통해 데이터가 모든 노드에 전파
이 예제는 웹툰/웹소설 플랫폼에서 흔히 볼 수 있는 BASE 특성을 잘 보여준다:
- 빠른 응답을 위한 비동기 통계 처리
- 일시적인 조회수/좋아요 데이터 불일치 허용
- 최종적으로는 정확한 통계 제공
3.4. BASE의 특징 요약
| 속성 | BASE |
|---|---|
| 일관성 수준 | 최종적 일관성 (Eventually Consistent) |
| 중점 사항 | 높은 가용성과 성능 |
| 적용 환경 | 분산 시스템 (NoSQL) |
| 사용 사례 | SNS 피드, 로그 시스템, 추천 시스템 |
| 대표 기술 | Cassandra, MongoDB |
- BASE는 SNS 피드, 로그 시스템, 추천 시스템처럼 실시간 응답성과 확장성이 중요한 환경에서 적합하다.
- MongoDB와 Cassandra 같은 NoSQL 데이터베이스는 이러한 요구사항을 충족하며, 가용성과 성능을 극대화하기 위해 설계되었다.
4. ACID vs BASE 비교
ACID와 BASE는 데이터베이스 설계 철학에서 서로 다른 우선순위를 가지며, 각각의 특성은 시스템 요구사항에 따라 적합한 선택이 된다.
4.1. ACID와 BASE의 차이
| 속성 | ACID | BASE |
|---|---|---|
| 일관성 수준 | 강한 일관성 (Strong Consistency) | 최종적 일관성 (Eventually Consistent) |
| 가용성 | 낮음 (일관성을 우선) | 높음 (가용성을 우선) |
| 트랜잭션 격리 | 강한 격리성 | 약한 격리성 |
| 데이터 상태 | 단단한 상태 (Hard State) | 부드러운 상태 (Soft State) |
| 중점 사항 | 데이터 무결성과 안정성 | 확장성과 성능 |
| 적용 환경 | 금융 거래, 재고 관리, 예약 시스템 | SNS 피드, 로그 처리, 추천 시스템 |
| 대표 기술 | MySQL, PostgreSQL | MongoDB, Cassandra |
4.1.1. 데이터 일관성 vs 가용성
- ACID
- 데이터를 즉시 일관된 상태로 유지해야 하는 경우 적합.
- 예: 금융 거래 시스템에서 데이터 무결성이 필수적.
- BASE
- 데이터가 일시적으로 불일치해도 괜찮으며, 최종적으로만 일관성을 보장.
- 예: SNS 피드에서 실시간으로 업데이트되지 않아도 사용자는 큰 불편을 느끼지 않음.
4.1.2. 성능과 확장성
- ACID
- 트랜잭션 잠금(locking)과 같은 오버헤드로 인해 성능이 제한될 수 있음.
- 수평 확장이 어려운 경우가 많음(단일 노드 중심 설계).
- BASE
- 분산 시스템에서 노드를 추가하여 수평 확장이 가능.
- 높은 쓰기/읽기 성능을 제공하며 대규모 데이터를 처리하기 적합.
4.2. 선택 기준
4.2.1. 비즈니스 요구사항
- 데이터 정확성이 중요한 경우:
- 금융 거래, 재고 관리 등 → ACID
- 빠른 응답 속도가 중요한 경우:
- SNS 피드, 실시간 로그 처리 등 → BASE
4.2.2. 데이터 특성
- 구조화된 데이터:
- 관계형 데이터베이스(RDBMS)가 적합 → ACID
- 비구조화된 데이터:
- NoSQL 데이터베이스가 적합 → BASE
4.2.3. 시스템 규모
- 소규모 시스템:
- 단일 서버 기반으로 설계 가능 → ACID
- 대규모 분산 시스템:
- 노드 확장이 필요한 경우 → BASE
4.3. 요약
- ACID는 높은 데이터 무결성과 안정성을 요구하는 환경에 적합하며, 주로 금융 및 예약 시스템에서 사용된다.
- BASE는 높은 가용성과 확장성이 필요한 환경에 적합하며, SNS 피드나 로그 처리와 같은 대규모 분산 시스템에서 사용된다.
- CAP 이론에 따라 둘 중 하나를 선택할 때, 비즈니스 요구사항(데이터 정확성 vs 빠른 응답 속도)과 시스템 특성을 고려해야 한다.
이러한 차이를 바탕으로 프로젝트 요구사항에 맞는 데이터베이스 모델을 선택하는 것이 중요하다.
5. 실전 적용 사례
ACID와 BASE를 함께 사용하는 경우, 각 모델의 장점을 활용하여 시스템의 요구사항을 충족시킬 수 있다.
- 예: 주문 처리는 ACID로, 제품 추천은 BASE로 구현
5.1. 상황에 따른 선택
- 이커머스 플랫폼
이커머스 플랫폼은 금융 거래와 재고 관리에는 ACID를 사용하여 데이터 정확성을 보장하고, 사용자 경험과 관련된 기능에는 BASE를 적용하여 높은 가용성과 성능을 제공한다.
- ACID: 주문 처리, 결제, 재고 관리
- BASE: 제품 리뷰, 추천 시스템, 사용자 활동 로그
- 실시간 채팅 서비스
- ACID: 사용자 인증, 메시지 저장
- BASE: 메시지 전송, 상태 업데이트, 사용자 온라인 상태
- 결제 시스템
- ACID: 실제 금액 이체, 잔액 관리
- BASE: 거래 내역 조회, 통계 분석, 사용자 활동 로그
5.2. 구체적 예시 (하이브리드 접근)
웹툰/웹소설 플랫폼에서도 데이터의 특성에 따라 ACID와 BASE를 함께 사용할 수 있다.
1. PostgreSQL (ACID)로 관리하는 데이터
- 콘텐츠 메타데이터: 작품 정보, 작가 정보, 에피소드 정보 등
- 결제/구매 데이터: 코인 충전, 에피소드 구매 내역
- 회원 데이터: 사용자 계정, 구독 정보
-- PostgreSQL: 콘텐츠 메타데이터 테이블
CREATE TABLE contents (
content_id VARCHAR(50) PRIMARY KEY,
title VARCHAR(200) NOT NULL,
author VARCHAR(100) NOT NULL,
description TEXT,
genre VARCHAR(50),
status VARCHAR(20) NOT NULL,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 에피소드 테이블
CREATE TABLE episodes (
episode_id VARCHAR(50) PRIMARY KEY,
content_id VARCHAR(50) REFERENCES contents(content_id),
title VARCHAR(200) NOT NULL,
episode_number INT NOT NULL,
coin_price INT NOT NULL,
publish_date TIMESTAMP NOT NULL
);2. MongoDB (BASE)로 관리하는 데이터
- 통계 데이터: 조회수, 좋아요 수, 별점
- 사용자 활동 로그: 최근 본 작품, 관심 작품
- 추천 데이터: 인기 작품, 추천 작품
// MongoDB: 통계 데이터 컬렉션
db.content_stats.updateOne(
{ contentId: "webtoon123" }, // PostgreSQL의 content_id 참조
{
$inc: { viewCount: 1 },
$setOnInsert: {
title: "판타지 웹툰", // 캐싱용 기본 정보
genre: "판타지", // 빠른 조회를 위한 중복 저장
thumbnailUrl: "...", // 자주 사용되는 정보
createdAt: new Date()
}
},
{ upsert: true }
)
// 사용자 활동 로그
db.user_activities.updateOne(
{
userId: "user123",
contentId: "webtoon123"
},
{
$set: {
lastReadEpisode: 15,
lastReadAt: new Date(),
isBookmarked: true
}
},
{ upsert: true }
)3. 데이터 연동 방식
- ID 참조
- MongoDB의 문서는 PostgreSQL의 PK(content_id)를 참조
- 데이터 정합성은 애플리케이션 레벨에서 관리
- 데이터 동기화 및 조회 최적화
// 동기화
// 예: 작품 정보 업데이트 시
@Transactional
public void updateContent(Content content) {
// 1. PostgreSQL 업데이트 (메인 데이터)
contentRepository.save(content);
// 2. MongoDB 캐시 데이터 업데이트 (비동기)
CompletableFuture.runAsync(() -> {
mongoTemplate.updateFirst(
Query.query(Criteria.where("contentId").is(content.getId())),
Update.update("title", content.getTitle())
.set("genre", content.getGenre())
.set("updatedAt", new Date()),
"content_stats"
);
});
}
// 조회 최적화
public ContentDetails getContentDetails(String contentId) {
// 1. PostgreSQL에서 기본 정보 조회
Content content = contentRepository.findById(contentId);
// 2. MongoDB에서 통계 정보 조회 (비동기)
CompletableFuture<ContentStats> statsFuture = CompletableFuture.supplyAsync(
() -> mongoTemplate.findById(contentId, ContentStats.class)
);
// 3. 데이터 결합
ContentStats stats = statsFuture.get(100, TimeUnit.MILLISECONDS);
return new ContentDetails(content, stats);
}
이러한 하이브리드 구조의 장점
- 중요 데이터는 ACID로 안전하게 관리
- 통계/로그 데이터는 BASE로 빠르게 처리
- 캐싱을 통한 조회 성능 최적화
- 각 데이터베이스의 장점을 최대한 활용
6. 마치며
6.1. 요약
ACID는 주로 일관성을 우선하지만, BASE는 가용성과 분할 내성을 우선한다.
관계형 데이터베이스(RDBMS)는 ACID를 따르고, 분산 데이터베이스(NoSQL)는 BASE를 따른다.
선택 기준은 다음과 같다.
- 데이터 무결성과 강한 일관성이 중요한 경우 → ACID
- 금융 거래, 재고 관리 등
- 구조화된 데이터를 다루는 경우
- 소규모 시스템에서 단일 서버 기반 설계가 가능한 경우
- 높은 가용성과 확장성이 중요한 경우 → BASE
- SNS 피드, 실시간 로그 처리 등
- 비구조화된 데이터를 다루는 경우
- 대규모 분산 시스템에서 노드 확장이 필요한 경우
이러한 특성을 이해해 구분하면, 시스템 설계 시 요구사항에 맞는 데이터베이스를 선택할 수 있다.
6.2. 참고 문헌
- [ACID #1] Transaction이란? - JS - 티스토리
- goover - ACID와 BASE 데이터베이스의 차이점 및 CAP 정리 이해
- Inpa Dev 👨💻:티스토리 - [MYSQL] 📚 트랜잭션(Transaction) 개념 & 사용 💯 완벽 정리
- aws blog - ACID 데이터베이스와 BASE 데이터베이스의 차이점은 무엇인가요?
- ACID 트랜잭션
- 데이터베이스 트랜잭션을 관리하고 ACID 속성을 구현하는 방법
- [Database] 트랜잭션(Transaction)과 ACID 개념 - 거북한 개발자의 기록
- PostgreSQL - NewBean의 웹과 콩나무 - 티스토리
- 트랜잭션이란? ACID의 구체적인 사례로 Transaction을 이해해 보자 ...
- (2부) DB MVCC 이어서 설명합니다 ! MySQL & postgreSQL 예제와 ...
- [Database] 트랜잭션 ACID, DB 연결구조와 세션 - seungwook(TIL)
- SQL 정의, 특성, 기능, 예시, ACID
- DB 트랜잭션 (Transaction)의 ACID 속성과 분산시스템 BASE 속성
- Cassandra와 MongoDB - NoSQL 데이터베이스 간의 차이점 - AWS
- Working with NoSQL Technologies - 토리맘의 한글라이즈 프로젝트
- JAVA로 트랜잭션 구현하기 - velog
- What is difference between MongoDB and Cassandra - Lullu Lalla
- 채팅 시스템 NoSQL 특성 및 비교 분석 ( CAP, PACELC ) - velog
- [무언가에 대한 리뷰][테크영상리뷰][쉬운코드] 데이터베이스 트랜잭션(transaction)을 아십니까? 그리고 트랜잭션의 매우 중요한 속성들인 ACID를 아십니까? 모르신다면 들렀다 가시지요 - passionfruit200 - 티스토리
- ACID vs BASE - velog
- [DB] MongoDB를 활용한 로그 관리: 설계부터 확장까지 - velog
'Database' 카테고리의 다른 글
| NoSQL의 모든 것: 개념, 종류, MongoDB와 Redis 맛보기 (0) | 2025.04.08 |
|---|---|
| 정규화(Normalization): 중복 없는 데이터베이스 설계 (1NF - BCNF) (0) | 2025.04.07 |
| 효율적 쿼리란? - 서브쿼리와 조인, 뷰, 인덱스로 쿼리 최적화 (0) | 2025.04.07 |
| 웹 개발자라면 꼭 알아야 할 데이터베이스 기초 정리 (0) | 2025.04.07 |
| DBMS의 선택과 기준 - DB 종류 및 특징 (0) | 2025.02.23 |