Intro
“사용자가 주소창에 URL을 입력하면 어떻게 되는가?”
웹 개발자로서 이러한 질문을 받으면 어떻게 답변할지는 대강 정해져 있다.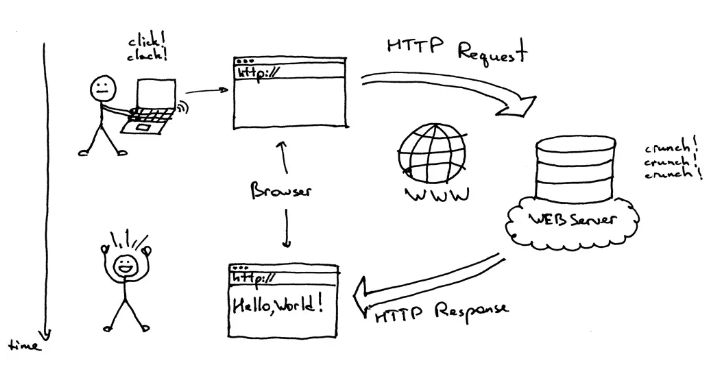
(출처: BrowserStack - What is Browser?
아주 간단하게는, "브라우저는 해당 URL로 요청을 보내고, 서버는 응답을 보내주고, 브라우저는 응답을 화면에 렌더링한다." 로 '요약'할 수 있다.
이런 짧은 답변 속에는 훨씬 복잡한 프로세스가 숨어 있다. 이 과정은 컴퓨터 과학의 거의 모든 영역을 아우른다.

(출처: TCP School - 웹의 동작 원리)
URL 입력부터 웹 페이지 표시까지 발생하는 모든 과정을 컴퓨터 과학적 관점과 브라우저 동작 관점에서 종합적으로 살펴보겠다. 간단한 질문에 답하기까지 브라우저 기본 구조, 네트워크 요청과 서버 응답, 보안 등 최대한 알아보자.
더 나은 성능과 사용자 경험을 제공하는 웹사이트를 구축하는 데 필수적인 지식이니 프론트, 백엔드 구분 없이 알아놓는 게 좋다.
1. 브라우저의 핵심 구성요소

(출처: BrowserStack - What is a Browser? How does it Work?)
브라우저가 어떻게 동작하는지 알아보기 전에 브라우저 구성 요소를 살펴보자.
현대 웹 브라우저는 다음 7가지 주요 구성요소로 이루어져 있다.
아래 프로세스들은 브라우저 내부에서 동작하며, 각 프로세스는 서로 독립적으로 작동한다. 이러한 분리는 보안을 강화하고, 안정성을 높이며, 메모리 누수를 방지하는 데 도움이 된다.
- 사용자 인터페이스(UI): 주소창, 버튼, 탭 등 사용자가 직접 상호작용하는 부분
- 브라우저 엔진(Browser Engine): UI와 렌더링 엔진 사이의 중재자 역할
- 렌더링 엔진(Rendering Engine): HTML/CSS를 파싱하고 화면에 표시하는 핵심 엔진
- 네트워킹(Networking): HTTP 요청 및 네트워크 통신 처리
- JavaScript 엔진(JavaScript Engine): JavaScript 코드 실행(예: Chrome의 V8)
- UI 백엔드(UI Backend): 기본 UI 요소 그리기 담당
- 데이터 저장소(Data Storage): 쿠키, 로컬 스토리지 등 관리

(출처: Chrome for Developers - Inside look at modern web browser (part 1))
브라우저는 멀티 프로세스 아키텍처를 사용하여 안정성과 보안성을 높인다.
- 브라우저 프로세스(Browser Process): UI와 네트워크 조정 담당
- 렌더러 프로세스(Renderer Process): 웹 콘텐츠 처리(탭마다 별도 프로세스)
- GPU 프로세스(GPU Process): 그래픽 처리 최적화
- 플러그인/유틸리티 프로세스(Plugin/Utility Process): 기타 기능 관리
*참고: 자세한 내용이 담긴 영상: 가장 쉬운 웹개발 with Boaz - Browser rendering process 1편 - Browser 구성 요소
2. URL 입력부터 네트워크 요청까지
2.1. 사용자 입력 분석

(출처: Chrome for Developers - Inside look at modern web browser (part 2))
사용자가 URL을 입력하면 브라우저의 UI 스레드가 이를 검사하여 검색어인지 URL인지 판단한다. URL로 판단되면 프로토콜, 도메인, 경로 등으로 파싱한다.
// 브라우저의 URL 판단 및 파싱 로직(개념적)
if (isValidURLFormat(input)) {
const parsedURL = {
protocol: extractProtocol(input), // 'https'
domain: extractDomain(input), // 'example.com'
path: extractPath(input), // '/page'
query: extractQuery(input) // '?param=value'
};
initiateNavigation(parsedURL);
} else {
performSearch(input);
}2.2. DNS 조회: 도메인에서 IP 주소로
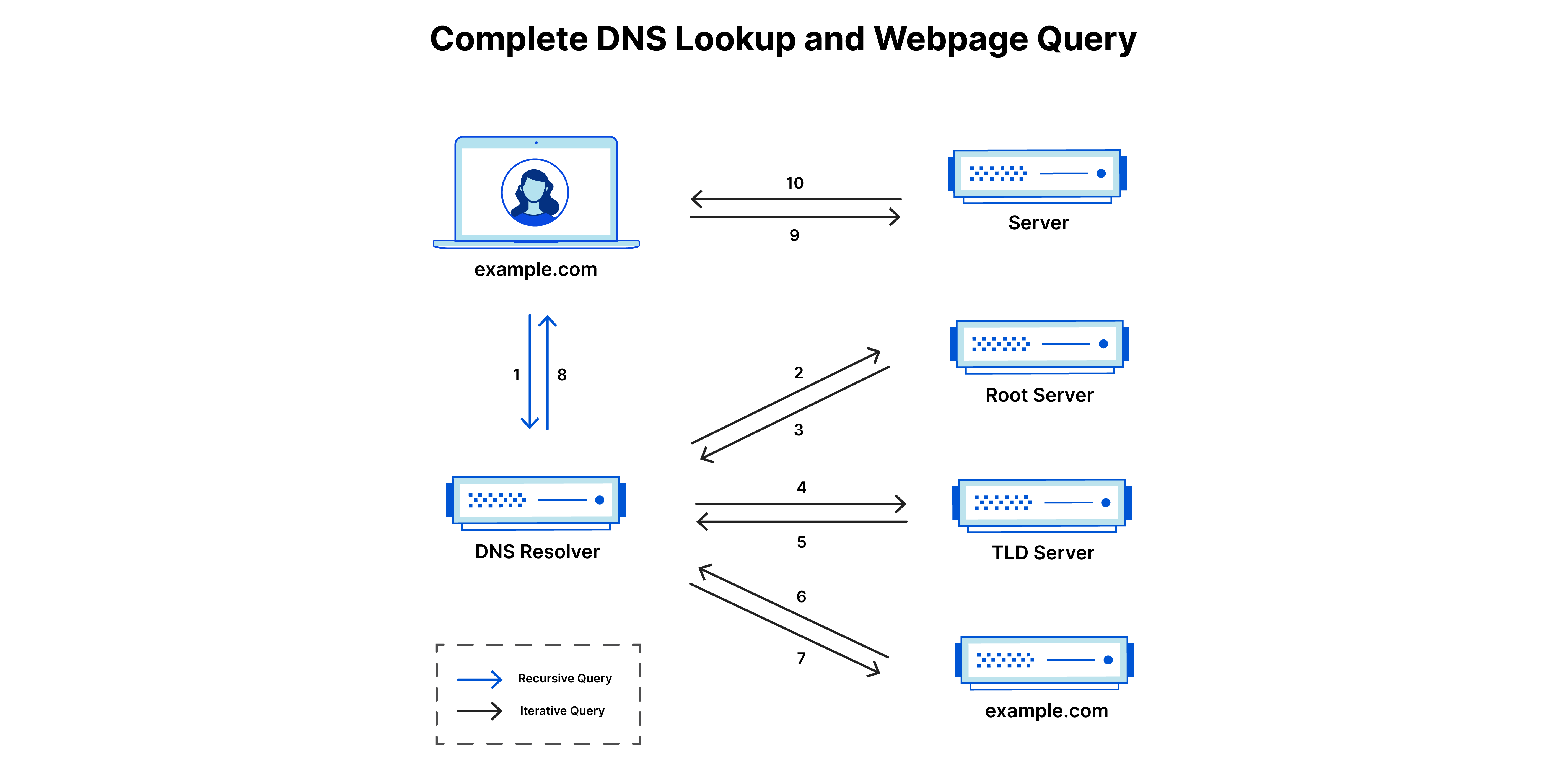
(출처: Cloudflare - DNS Lookup Information)
도메인 이름(예: example.com)을 실제 IP 주소로 변환하는 과정이다. 브라우저는 다음 순서로 DNS 정보를 찾는다.
- 브라우저 캐시
- 운영체제 캐시
- 라우터 캐시
- ISP(인터넷 서비스 제공업체) DNS 서버
- 루트 DNS 서버부터의 재귀적 조회
각 단계는 성공적으로 찾으면 다음 단계로 진행하지 않아 시간을 절약한다. 최종적으로 도메인의 IP 주소(예: 93.184.216.34)를 얻게 된다.
2.3. TCP 연결과 TLS 핸드쉐이크

(출처: Cloudflare - What is a TLS handshake?)
IP 주소를 확보한 후, 브라우저는 서버와 TCP 연결을 수립한다. 이는 '3-way 핸드쉐이크'라고 불리는 과정을 통해 이루어진다.
- 클라이언트 → 서버: SYN 패킷 전송
- 서버 → 클라이언트: SYN-ACK 패킷 응답
- 클라이언트 → 서버: ACK 패킷 전송
HTTPS 사이트의 경우, TLS 핸드쉐이크가 추가로 진행된다.
- 클라이언트가 지원하는 암호화 방식 정보 전송
- 서버가 암호화 방식과 인증서 전송
- 클라이언트가 인증서 검증 및 대칭 키 생성
- 암호화된 통신 채널 확립
2.4. HTTP 요청 및 응답
TCP/TLS 연결이 수립되면 브라우저는 HTTP 요청을 생성하여 전송한다.
GET /index.html HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0 ...
Accept: text/html,application/xhtml+xml,...서버는 이 요청을 처리하고 응답을 반환한다:
HTTP/1.1 200 OK
Content-Type: text/html; charset=UTF-8
Content-Length: 1256
<!DOCTYPE html>
<html>...2.5. 서비스 워커와 캐싱 전략
현대 웹 애플리케이션은 서비스 워커를 통해 네트워크 요청을 제어할 수 있다. 서비스 워커는 브라우저와 서버 사이의 프록시 역할을 하며, 오프라인 경험 제공, 캐싱 전략 구현 등에 활용된다.
중요한 최적화 기법으로는 네비게이션 프리로드가 있다. 이는 서비스 워커 시작과 병행하여 네트워크 요청을 미리 시작함으로써 페이지 로딩 시간을 단축한다.
3. 브라우저의 렌더링 과정
3.1. HTML 파싱과 DOM 트리 구축
서버로부터 HTML을 받으면 렌더러 프로세스는 이를 파싱하여 DOM(Document Object Model) 트리를 구축한다:
<!DOCTYPE html>
<html>
<head>
<title>예제</title>
<link rel="stylesheet" href="styles.css">
</head>
<body>
<h1>안녕하세요!</h1>
<p>이것은 <span>예제</span>입니다.</p>
</body>
</html>이 HTML은 다음과 같은 DOM 트리로 변환된다:
Document
└── html
├── head
│ ├── title: "예제"
│ └── link[rel="stylesheet"]
└── body
├── h1: "안녕하세요!"
└── p
├── "이것은 "
├── span: "예제"
└── "입니다."HTML 파싱 중 외부 리소스(<link>, <script>, <img>)를 발견하면 추가 네트워크 요청이 발생한다.
3.2. CSS 처리와 CSSOM 구축
CSS가 로드되면 브라우저는 이를 파싱하여 CSSOM(CSS Object Model)을 생성한다. CSSOM은 모든 스타일 정보를 계층적으로 구조화한 것이다.
스타일 계산은 다음과 같은 우선순위로 이루어진다:
- 브라우저 기본 스타일
- 사용자 스타일시트
- 외부 스타일시트
- 내부 스타일시트
- 인라인 스타일
CSS 선택자의 특이성과 선언 순서도 스타일 적용에 영향을 미친다.
3.3. 렌더 트리 구축과 레이아웃 계산
DOM과 CSSOM이 결합되어 렌더 트리가 생성된다. 렌더 트리는 실제로 화면에 표시될 요소만 포함한다(display: none이 적용된 요소는 제외).
레이아웃 단계에서는 각 요소의 정확한 위치와 크기가 계산된다. 이 과정에서 요소의 박스 모델, 포지셔닝, 플로팅 등이 고려된다.
3.4. 페인팅과 컴포지팅
페인팅 단계에서는 계산된 레이아웃이 실제 픽셀로 변환된다. 이 과정은 여러 레이어로 나뉘어 처리될 수 있다.
컴포지팅은 이렇게 나뉜 레이어들을 하나로 합성하는 과정이다. 현대 브라우저는 하드웨어 가속을 활용해 이 과정을 GPU로 처리하여 성능을 최적화한다.
/* GPU 가속을 활용하는 CSS 속성 예시 */
.hardware-accelerated {
transform: translateZ(0);
will-change: transform;
}3.5. JavaScript 실행과 DOM 조작
HTML 파싱 중 <script> 태그를 만나면 JavaScript 엔진이 코드를 실행한다. JavaScript는 DOM API를 통해 웹 페이지를 동적으로 변경할 수 있다.
// DOM 요소 생성 및 추가
const newElement = document.createElement('div');
newElement.textContent = '동적으로 추가된 콘텐츠';
document.body.appendChild(newElement);
// 스타일 변경
document.getElementById('header').style.color = 'blue';이러한 DOM 조작은 레이아웃 재계산(리플로우)과 페인팅을 다시 발생시킬 수 있어, 성능에 영향을 미칠 수 있다.
4. 컴퓨터 과학 관점에서의 브라우저 동작
4.1. 프로세스와 스레드 관리
브라우저는 운영체제의 프로세스와 스레드 모델을 활용한다. 크롬과 같은 모던 브라우저는 여러 프로세스로 작업을 분리하여 안정성을 높이고, 각 프로세스 내에서는 여러 스레드가 병렬로 작업을 처리한다.
렌더러 프로세스 내의 주요 스레드들:
- 메인 스레드: HTML 파싱, JavaScript 실행, 레이아웃 계산
- 컴포지터 스레드: 레이어 합성 및 부드러운 스크롤 처리
- 래스터라이저 스레드: 픽셀 변환 작업
- 워커 스레드: 백그라운드 작업 처리
4.2. IPC(Inter-Process Communication)
브라우저의 여러 프로세스들은 IPC를 통해 안전하게 통신한다.
- 브라우저 프로세스 → 렌더러 프로세스: "이 URL을 렌더링하세요"
- 렌더러 프로세스 → 브라우저 프로세스: "이 네트워크 요청을 보내주세요"
이러한 분리는 보안을 강화하지만, 통신 오버헤드가 발생할 수 있다.
4.3. CPU와 GPU의 역할 분담
- CPU: 주로 HTML 파싱, JavaScript 실행, 레이아웃 계산 등 논리적 처리 담당
- GPU: 그래픽 렌더링, 애니메이션, 컴포지팅 등 시각적 처리 담당
현대 웹 애플리케이션은 CSS 변형, 애니메이션, 캔버스 조작 등을 GPU로 오프로드하여 성능을 최적화한다.
4.4. 사이트 격리(Site Isolation)
크롬의 사이트 격리는 보안을 강화하는 중요한 기능이다. 이는 각 사이트(심지어 iframe까지)를 별도의 렌더러 프로세스에서 실행하여, 사이트 간 메모리 공유를 방지한다. 이는 특히 Spectre나 Meltdown 같은 사이드 채널 공격에 대한 방어책이 된다.
5. 서버의 역할
5.1. HTTP 요청 처리
서버는 브라우저로부터 받은 HTTP 요청을 다음과 같이 처리한다.
- 요청 파싱: HTTP 메서드, URL, 헤더 분석
- 라우팅: 요청된 리소스에 맞는 핸들러로 전달
- 인증/권한 검사: 필요시 사용자 인증 및 권한 확인
- 비즈니스 로직 실행: 요청에 맞는 작업 수행
- 응답 생성: 처리 결과를 HTTP 응답 형태로 변환
- 응답 전송: 클라이언트에게 반환
5.2. 데이터베이스 상호작용
많은 웹 애플리케이션은 데이터베이스와 연결되어 있다. 서버는 데이터베이스에 연결하고, 쿼리를 실행하며, 결과를 처리하여 웹 페이지를 동적으로 생성한다.
대규모 웹사이트는 성능 최적화를 위해 캐싱 레이어(Redis, Memcached 등)를 활용하여 데이터베이스 부하를 줄인다.
6. 웹 성능과 최적화
브라우저가 페이지를 로드하고 표시하는 과정을 이해하면 성능 최적화에 도움이 된다. 주요 성능 지표로는 다음과 같은 것들이 있다.
- FP(First Paint): 첫 픽셀이 그려지는 시점
- FCP(First Contentful Paint): 텍스트/이미지가 처음 표시되는 시점
- LCP(Largest Contentful Paint): 주요 콘텐츠가 표시되는 시점
- TTI(Time to Interactive): 사용자와 상호작용 가능한 시점
- CLS(Cumulative Layout Shift): 레이아웃 변화의 누적 점수
최적화 전략으로는 다음과 같은 것들이 있다.
- 중요 리소스 미리 로드(preload)
- 지연 로딩(lazy loading)
- 코드 분할(code splitting)
- 이미지 최적화
- 서비스 워커 활용
- HTTP 캐싱 설정
결론
브라우저 주소창에 URL을 입력하는 간단한 행동은 컴퓨터 과학의 거의 모든 영역을 아우르는 복잡한 과정을 시작한다. 이 과정을 단계별로 요약하면, 아래와 같다.
- URL 입력 및 파싱
- DNS 조회로 IP 주소 찾기
- TCP/TLS 연결 수립
- HTTP 요청 전송 및 응답 수신
- HTML 파싱 및 DOM 구축
- CSS 처리 및 CSSOM 생성
- JavaScript 실행
- 렌더 트리 생성, 레이아웃 계산, 페인팅, 컴포지팅
- 최종 화면 표시
이 모든 과정이 불과 몇 백 밀리초 안에 이루어진다. 이러한 기본 원리를 이해하는 게 더 나은 사용자 경험을 제공하는 웹사이트를 구축하는 데 도움이 될 것이다.
브라우저의 작동 방식을 이해는 웹 개발의 필수 토대가 되는 만큼 기초적인 내용이지만 생각보다 방대할 정도로 종합적인 지식이 담기는 내용이다.
참고 자료
- Chrome Developers. "Inside look at modern web browser." https://developer.chrome.com/blog/inside-browser-part1
- MDN Web Docs. "HTTP." https://developer.mozilla.org/docs/Web/HTTP
- TCP School. "웹의 동작 원리." https://tcpschool.com/webbasic/works
- W3C. "HTML Living Standard." https://html.spec.whatwg.org/
- Google Developers. "Web Performance." https://web.dev/performance
'Network' 카테고리의 다른 글
| 프록시와 스케일링: 안정적인 트래픽 처리 (2) | 2025.03.26 |
|---|---|
| [3편] 브라우저는 어떻게 나를 기억할까? - HTTP 활용 (2) | 2025.03.26 |
| [2편] HTTP 메서드부터 상태 코드, 주요 헤더까지 (0) | 2025.03.26 |
| [1편] 브라우저는 어떻게 서버를 찾을까? – DNS와 HTTP 메시지 구조까지 (0) | 2025.03.26 |