
1. 개요: 왜 NoSQL인가?
프로젝트에서 대용량 데이터를 다루거나 수평적 확장이 필요한 상황이라면, RDBMS 대신 NoSQL을 검토해본 적이 있을 것입니다.
📌 NoSQL의 의미
NoSQL은 'Non-SQL' 또는 'Not only SQL'로 해석되며,
SQL처럼 특정 쿼리 언어를 지칭하는 것이 아닌
새로운 데이터베이스 패러다임을 의미합니다.
전통적인 관계형 데이터베이스의 제약에서 벗어나
데이터를 더 자유롭고 유연한 형태로 저장하고 관리하는 접근 방식입니다.
이 글에서는 NoSQL의 주요 네 가지 종류를 구체적으로 비교하고,
왜 NoSQL이 주목받는지, MongoDB와 Redis의 기본 사용법까지 실습 방법을 공유합니다.
📖 참고: 이 글은 『이것이 취업을 위한 컴퓨터 과학이다』 CHAPTER 06, p.605 ~ p.620의 내용을 기반으로 한 설명입니다.
2. RDBMS vs NoSQL: 무엇이 다른가?
관계형 데이터베이스(RDBMS)는 정형 데이터, 스키마 고정, ACID 트랜잭션을 강점으로 삼습니다.
하지만 대규모 사용자 요청과 다양한 형태의 비정형 데이터를 처리하기엔 한계가 있습니다.
반면, NoSQL은 다음과 같은 특성을 가집니다.
- 스키마 유연성: 구조가 자유로워 다양한 형태의 데이터를 저장 가능
- 수평적 확장성: 서버를 늘려 성능 개선
- 고가용성: 장애 발생 시 빠른 복구 가능
- ACID보다는 BASE(Basically Available, Soft state, Eventual consistency) 지향
🤔 생각해보기
NoSQL이라는 용어는 단순히 "SQL이 아닌"이라는 의미를 넘어서,
어떤 특별한 가치와 장점을 제공할까요?
RDBMS와 비교했을 때 가장 두드러지는 차이점은 무엇일까요?
☞ 관계형 데이터베이스는 테이블 기반의 구조로서 스키마가 고정되어 있는 반면, 비관계형 데이터베이스인 NoSQL 데이터베이스는 데이터의 저장 및 관리를 위해 고정된 스키마가 없고, 수평 확장이 용이한 구조를 가지고 있습니다. NoSQL 데이터베이스는 키-값, 도큐먼트, 칼럼 패밀리, 그래프 등의 다양한 형태로 저장할 수 있습니다.
3. NoSQL의 네 가지 대표 유형
3.1 키-값(Key-Value) 데이터베이스
- 대표 사례: Redis, Memcached
- 구조: 단순히
키(key)와값(value)으로 구성 - 특징:
- 매우 빠른 읽기/쓰기 속도
- 대부분 인메모리(in-memory) 기반으로 동작 → 디스크보다 빠름
- 단순 조회에 적합하지만, 복잡한 쿼리는 부적합
📌 인메모리 DB란?
데이터를 디스크가 아닌 RAM에 저장하여 초고속으로 접근 가능한 DB입니다. Redis, Memcached가 대표적입니다.
🤔 생각해보기
인메모리 데이터베이스는 데이터를 메모리에 저장하므로 재시작 시 데이터가 손실될 수 있습니다.
그렇다면 Redis와 같은 인메모리 DB들은 이 문제를 어떻게 해결할까요?
☞ Redis는 RDB(Redis Database) 스냅샷과 AOF(Append Only File) 방식을 통해 데이터 영속성을 보장합니다. RDB는 특정 시점의 데이터를 디스크에 저장하고, AOF는 모든 쓰기 명령을 로그로 저장하여 재시작 시 데이터를 복구할 수 있게 합니다.
3.2 도큐먼트(Document) 데이터베이스
- 대표 사례: MongoDB
- 구조: JSON 또는 BSON 형식의 도큐먼트 단위로 저장
- 특징:
- 도큐먼트 하나가 하나의 레코드를 구성
- 필드마다 타입이 달라도 저장 가능 (스키마 유연성)
- 중첩된 데이터(배열, 객체) 구조도 표현 가능
MongoDB는 NoSQL의 대표 주자로, RDBMS의 테이블 → 컬렉션, 행 → 도큐먼트로 대응됩니다.

🤔 생각해보기
MongoDB는 스키마가 자유롭다고 하지만, 완전히 제약이 없는 것은 아닙니다.
데이터의 일관성과 유효성을 어떻게 보장할 수 있을까요?
☞ MongoDB는 JSON Schema 검증, 인덱싱, 애플리케이션 레벨의 검증 로직을 통해 데이터 일관성을 유지할 수 있습니다. 특히 MongoDB 3.6 버전부터는 컬렉션 레벨에서 스키마 검증을 설정할 수 있어, 필요한 경우 RDBMS처럼 엄격한 스키마 제약도 가능합니다.
3.3 그래프(Graph) 데이터베이스

- 대표 사례: Neo4j
- 구조: 노드(Node)와 간선(Edge)으로 구성된 방향 그래프
- 특징:
- 노드 간 관계를 빠르게 탐색 가능
- 소셜 미디어 친구 관계, 교통망, 추천 시스템 등 관계형 데이터에 적합
- 복잡한 JOIN을 단순한 그래프 탐색으로 대체
🧠 그래프 구조의 핵심은 노드 간 연결 관계를 직접 저장하고 탐색할 수 있는 성능에 있습니다.
🤔 생각해보기
소셜 미디어나 추천 시스템에서 그래프 데이터베이스가 RDBMS보다 효율적인 이유는 무엇일까요?
☞ 예를 들어 "친구의 친구 찾기"와 같은 기능을 구현할 때, RDBMS에서는 여러 번의 JOIN 연산이 필요하지만, 그래프 DB에서는 노드 간 관계를 직접 탐색할 수 있어 매우 효율적입니다. 특히 LinkedIn과 같은 소셜 네트워크에서 "n차 연결" 기능을 구현할 때 그래프 DB의 장점이 두드러집니다.
why?
그래프 데이터베이스가 SNS나 추천 시스템에서 RDBMS보다 효율적인 이유는 데이터 탐색 방식과 데이터 모델링의 유연성에 있습니다. RDBMS에서는 "친구의 친구"를 찾기 위해 여러 번의 JOIN 연산을 수행해야 하며, 탐색 깊이가 깊어질수록 계산량이 기하급수적으로 증가합니다.
반면, 그래프 데이터베이스는 노드(사용자)와 엣지(관계)를 물리적으로 연결된 상태로 저장하여 직접 포인터를 따라 탐색하므로 탐색 복잡도가 선형적으로 증가(O(n))하며 매우 빠릅니다. 또한 그래프 DB는 스키마가 없거나 유연한 구조를 제공해 새로운 관계 유형을 쉽게 추가할 수 있고, 엣지에 가중치나 속성을 저장하여 추천 시스템에서 고급 분석을 가능하게 합니다.
특히 LinkedIn과 같은 소셜 네트워크에서 "n차 연결" 기능을 구현할 때:
그래프 DB는 엣지를 따라 실시간으로 관계를 탐색할 수 있어 대규모 연결 데이터를 효율적으로 처리할 수 있으며, 그래프 알고리즘(PageRank, 최단 경로 등)을 활용해 사용자 간 관계망 분석이나 추천을 최적화할 수 있습니다.
이러한 이유로 SNS와 추천 시스템에서 그래프 데이터베이스는 RDBMS보다 더 적합한 선택입니다.
3.4 칼럼 패밀리(Column Family) 데이터베이스
- 대표 사례: Cassandra, HBase
- 구조: 행(Row)과 열(Column) 구조를 가지지만 스키마 고정 X
- 특징:
- 각 행마다 다른 열을 가질 수 있음
- 정규화나 JOIN 없이 사용 (데이터 중복을 허용)
- 대규모 쓰기/읽기에 강한 성능
📌 "칼럼 패밀리"란 연관된 열들을 묶어 저장하는 단위입니다. 한 패밀리 안에서 열 구조는 유연하게 변할 수 있습니다.

🤔 생각해보기
빅데이터 처리에서 칼럼 패밀리 데이터베이스가 선호되는 이유는 무엇일까요? 특히 데이터 압축과 조회 성능 측면에서 생각해봅시다.
☞ 데이터 저장 방식과 효율적인 읽기 성능 이점
칼럼 패밀리 DB는 데이터를 행(row) 단위가 아닌 열(column) 단위로 저장합니다. 같은 유형의 데이터를 물리적으로 인접하게 저장하므로, 데이터 압축 효율이 매우 높아지고 저장 공간을 절약할 수 있습니다. 예를 들어, 동일한 열에 반복적으로 나타나는 값(예: 센서 데이터의 상태 플래그)을 효과적으로 압축할 수 있습니다.
또한, 칼럼 단위로 데이터를 읽기 때문에 필요한 열만 선택적으로 조회할 수 있어 입출력(IO) 성능이 크게 향상됩니다. 이는 특히 대규모 데이터셋에서 일부 열만 자주 읽는 경우(예: 로그 분석에서 특정 필드만 조회) 매우 유리합니다. 이러한 특성 덕분에 칼럼 패밀리 DB는 센서 데이터, 로그 데이터, 시계열 데이터와 같이 대규모로 생성되고 특정 열에 집중된 분석이 필요한 빅데이터 처리에 적합합니다.
4. NoSQL을 선택하는 이유
NoSQL은 다음과 같은 상황에서 선택합니다.
| 조건 | RDBMS | NoSQL |
|---|---|---|
| 데이터 정형성 | 높음 | 낮음 |
| 트랜잭션 무결성(ACID) | 중요 | 덜 중요 |
| 수평적 확장 필요 여부 | 낮음 | 높음 |
| 데이터 관계 복잡성 | 높음 | 낮음~중간 |
| 빠른 읽기/쓰기 성능 | 일반적 | 매우 빠름 |
| 유연한 구조의 데이터 처리 필요 | 부족 | 매우 유연 |
⚠️ ACID를 아예 포기하는 것은 아닙니다. MongoDB, Cassandra 등은 상황에 따라 ACID 일부를 지원하거나 옵션으로 제공합니다.
🤔 생각해보기
데이터베이스 선택은 프로젝트의 성공을 좌우하는 중요한 결정입니다.
NoSQL과 RDBMS는 각각 어떤 상황에서 더 적합할까요?
NoSQL 데이터베이스는 대규모의 비정형 데이터를 처리할 때, 높은 확장성과 빠른 읽기/쓰기 성능이 필요할 때 유리합니다.
그러나 엄격한 트랜잭션 관리나 데이터 일관성 보장, 관계형 데이터 모델링이 필요한 애플리케이션에서는
관계형 데이터베이스가 더 적합하므로 NoSQL 데이터베이스는 불리할 수 있습니다.
5. 실습으로 이해하는 NoSQL
🛠 실습 전 준비
환경 설정은 강태공 GitHub 실습 자료를 참고해주세요.
MongoDB와 Redis 모두 로컬 혹은 Docker로 손쉽게 구성할 수 있습니다.
5.1 MongoDB 실습 요약
MongoDB에서 레코드는 도큐먼트 단위로 저장됩니다. 도큐먼트가 모여 컬렉션이 되고, 컬렉션이 모여 데이터베이스를 구성합니다.
# 데이터베이스 및 컬렉션 생성
use mydb
db.createCollection("mycollection")
# 단일 도큐먼트 삽입
db.mycollection.insertOne({ name: "Robin", age: 28 })
# 다중 도큐먼트 삽입
db.mycollection.insertMany([{ name: "Ash" }, { name: "Hanna" }])
# 도큐먼트 조회
db.mycollection.find()
📌 여기서 잠깐! MongoDB의 주요 연산자 정리
MongoDB는 $set, $inc, $push, $pull 등 연산자를 통해 도큐먼트 내부 필드를 유연하게 갱신할 수 있습니다. SQL의 UPDATE SET과 유사하지만, JSON 구조를 직접 조작한다는 점에서 차별화됩니다.
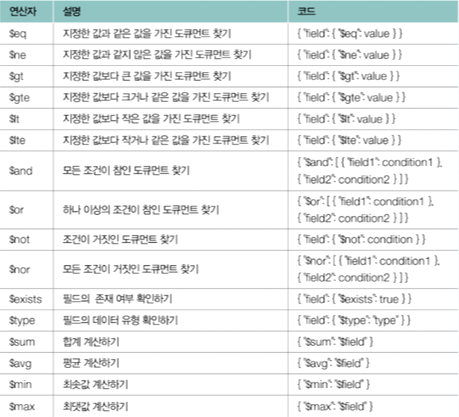
💡 Tip
- $set과 $eq는 거의 모든 MongoDB 작업에서 사용됩니다
- $in은 여러 조건을 한 번에 처리할 때 매우 유용합니다
- $inc는 카운터나 통계 처리에 필수적입니다
- 배열 처리는 $push와 $pull이 가장 기본입니다
5.2 Redis : 빠르고 유연한 인메모리 데이터베이스

Redis는 Remote Dictionary Server의 약자로, 인메모리 기반의 키-값 데이터베이스입니다.
모든 데이터를 RAM에 저장하여 초고속 성능을 제공하며,
데이터베이스, 캐시(Cache), 메시지 브로커, 세션 관리, 실시간 데이터 분석 등 다양한 용도로 활용됩니다.

Redis는 단순한 키-값 저장소를 넘어
문자열(String), 리스트(List), 해시(Hash), 집합(Set), 정렬된 집합(Sorted Set) 등
다양한 자료구조를 지원하여 애플리케이션의 요구사항에 유연하게 대응할 수 있습니다.
# 문자열 저장 및 조회
SET username "Robin"
GET username
# 리스트 연산
LPUSH tasks "task1"
RPUSH tasks "task2"
LRANGE tasks 0 -1 # 전체 리스트 조회
참고 : REDIS-📚-데이터-타입Collection-종류-정리

이러한 구조 덕분에 Redis는 지연 시간이 중요한 애플리케이션에서 널리 사용되며,
대규모 트래픽 환경에서도 안정적으로 작동합니다.
📌 장점: 빠른 속도와 유연성
데이터를 디스크가 아닌 RAM에 저장하기 때문에
읽기 및 쓰기 작업이 마이크로초 단위로 처리되며,
초당 수백만 건의 요청을 처리할 수 있습니다.
또한, Redis는 아래 3가지를 지원해 확장성과 고가용성을 제공합니다.
- 데이터 복제(Replication)
- 영속성(Persistence)
- 클러스터링(Clustering)
📌 Redis 활용 사례
Redis는 빠른 속도와 유연한 자료구조 덕분에 다음과 같은 다양한 상황에서 활용됩니다.
- 캐싱: 웹 애플리케이션에서 자주 조회되는 데이터를 저장하여 응답 시간을 단축.
- 메시지 브로커: Pub/Sub 기능을 활용해 실시간 알림 시스템 구현.
- 세션 관리: 사용자 로그인 세션을 관리하여 빠르게 접근 가능.
- 실시간 분석: 로그 데이터나 센서 데이터를 처리하여 실시간 통계를 제공.
- 순위표 및 리더보드: 정렬된 집합(Sorted Set)을 활용해 실시간 순위 계산.
🤔 생각해보기
많은 기업들이 Redis를 캐시 시스템으로 활용하고 있습니다.
Redis의 어떤 특성이 캐시 서버로서 특별한 가치를 제공하는 걸까요?
사용자의 로드 시간이 적을수록 전환율이 높습니다.
그런데 Redis는 인메모리 데이터베이스이기 때문에 디스크 접근 시간을 단축할 수 있습니다.
또한 Redis는 여러 자료구조를 지원하는 키-값 데이터베이스로써,
RDBMS보다 정형화되어 있지 않은 데이터에 대한 빠른 입출력이 가능합니다.
따라서 RDBMS 등을 주요 데이터베이스로 삼고,
Redis를 캐시 역할을 수행하는 부차적인 데이터베이스로 삼으면
주요 데이터베이스의 입출력 성능을 상당 부분 보강할 수 있습니다.
📌 Redis와 캐싱 패턴
캐싱은 시스템의 성능을 향상시키는 가장 쉬운 방법이라고 합니다.
Redis는 특히 캐시(Cache)로 자주 사용되며, 다양한 캐싱 전략 패턴이 있습니다.
- Static/Dynamic Caching : 데이터 변경 가능성과 일관성 유지 여부 기준
- Static: 읽기 전용, 변경 불가 → Cache-Aside, Write-Around.
- Dynamic: 읽기/쓰기 가능, 변경 가능 → Write-Through, Write-Back.
- 캐싱 전략 패턴 : 데이터 처리 흐름 기준
- Cache-Aside: 필요할 때만 캐시 사용. 가장 일반적.
- Write-Through: 실시간으로 캐시와 DB 동기화.
- Write-Around: 쓰기는 DB에만, 읽기는 캐시에서.
- Write-Back: 쓰기는 먼저 캐시에, 이후 비동기로 DB에 반영.
- Read-Through: 읽기를 자동으로 처리하며 필요 시 DB에서 가져옴.
참고
- https://minnseong.tistory.com/49
- https://velog.io/@zenon8485/%EC%BA%90%EC%8B%B1%EC%A0%84%EB%9E%B5
6. 마무리 및 배운 점
- NoSQL은 단순히 RDBMS의 대체재가 아닌, 특정 문제에 특화된 대안
- 정형 데이터, 트랜잭션 중심이면 여전히 RDBMS가 우위
- 반면, 유연성, 확장성, 속도가 중요하면 NoSQL이 탁월
- MongoDB와 Redis의 기본 동작 원리를 알아봄
💡 Tip: 실제 프로젝트에서는 RDBMS와 NoSQL을 혼합하여 사용하는 하이브리드 구조도 많이 사용됩니다.
7. 참고 자료
- 『이것이 취업을 위한 컴퓨터 과학이다』 CHAPTER 06, p.605 ~ p.620
- MongoDB - NoSQL이란 무엇입니까?
- 큰돌의터전 - MySQL과 MongoDB의 완벽한 비교
- 쉬운코드 - BJ.53 NoSQL 설명!! RDB와는 어떤 차이가 있는지도 설명!! MongoDB, Redis 매우 간단한 예제 포함!!
- Simply Explained - How do NoSQL databases work? Simply Explained!
- Anton Putra - Types of Databases: Relational vs. Columnar vs. Document vs. Graph vs. Vector vs. Key-value & more
- Awesome - The Fascinating History of Databases
- F-Lab 스프링 부트와 레디스를 활용한 캐싱 전략
📚 더 알아보기
- CAP 이론과 NoSQL의 일관성 모델: Eventually Consistent란?
- Redis의 TTL(Time to Live)과 만료 처리 전략
- MongoDB의 인덱싱 구조와 복합 인덱스 설계
'Database' 카테고리의 다른 글
| 샤딩 vs 파티셔닝, 무엇을 언제 선택해야 할까? – 데이터 분산 전략 (0) | 2025.04.09 |
|---|---|
| 정규화(Normalization): 중복 없는 데이터베이스 설계 (1NF - BCNF) (0) | 2025.04.07 |
| 효율적 쿼리란? - 서브쿼리와 조인, 뷰, 인덱스로 쿼리 최적화 (0) | 2025.04.07 |
| 웹 개발자라면 꼭 알아야 할 데이터베이스 기초 정리 (0) | 2025.04.07 |
| 데이터베이스 트랜잭션 ACID 특성과 BASE 데이터 일관성 모델 (3) | 2025.02.27 |